ARCHIVING
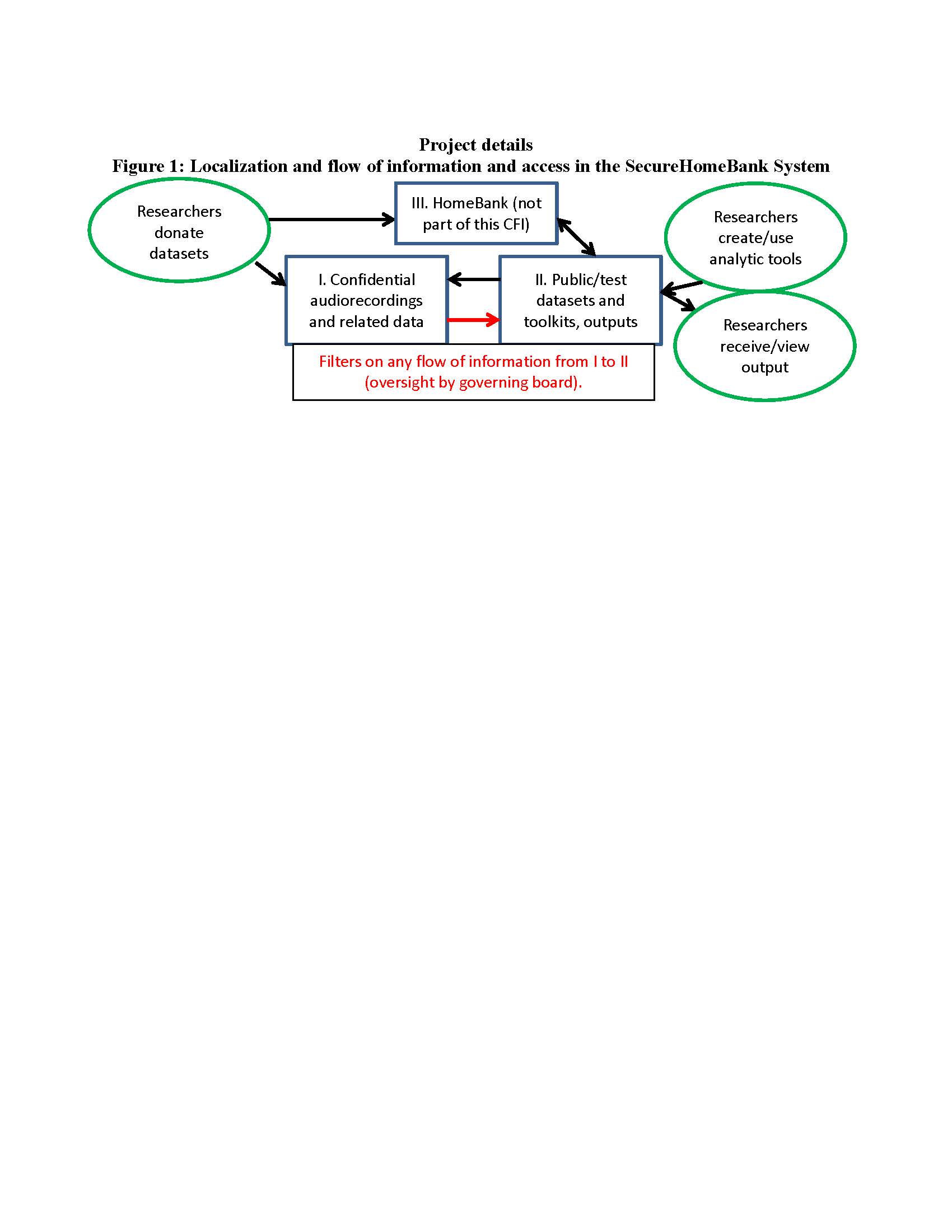
There are currently two ongoing initiatives to implement archiving, HomeBank and SecureHomeBank. There are a few differences between the two; one salient different pertains the type of data they will contain, with a typology set up in terms of how anonymized the data are.
We have defined four types:- Type 0, metadata: in the LENA system, this corresponds to .its files, containing timemarks of voice activity and a broad classification in terms of speaker (target child, adult male, adult female, etc). This meta data is almost totally anonymized (the date of birth might need to be removed), and does not contain any sensitive data; we are therefore envisioning of setting up an open data public archive for it. We would use a metadata file (like the one explained in this shared doc [1]) to be able to aggregate across datasets.
- Type 1, annotated data: the idea here is to use the CHILDES repository and format for both the audio files and the human annotated data, provided of course that the parents have agreed to make public such data (which can only be partly anonymized, because it contains for instance the voice). Yet, the experimenter should make sure that this recording does NOT contain any sensitive data (such as regards health, political or religious beliefs, etc).
- Type 2, raw data shareable with approved researchers: here, there is participant permission to share the data, but it has not been processed in any particular way, and hence it contains both personal and sensitive data. Such data should NOT be made totally public. Individual researchers can be granted access to this data, but will need to agree to certain terms of use and demonstrate training in research ethics, to ensure the privacy and confidentiality of the data are maintained.
- Type 3, raw data: here, the data has not been processed in any particular way, and hence contain both personal and sensitive data. Such data should NOT be made public as such and will be stored in an encrypted format on a secure server. This data can however be made accessible to approved algorithms (speech processing, machine learning, etc), provided they only extract anonymized derived data (Level 0). ONLY metadata would be accessible to researchers. (The process of approbation/certification of the algorithm needs to be defined).
The HomeBank initiative would therefore contain data of the types 0-2, while the SecureHomeBank initiative would have data of the types 0 and 3.